Quando estamos trabalhando com URLs e/ou APIs REST, precisamos com frequência converter uma string para um formato válido de URL, conhecido como URL encoded. Se estivermos trabalhando com o curl é tranquilo, já temos a nossa disposição a opção --data-urlencode. Mas quando não vamos usar o curl, podemos implementar nossa própria solução usando bash puro.
urlencode()
Eis o código:
#!/usr/bin/env bash
#
# urlencode - codificando sua string para usar em URLs
urlencode() {
local LC_ALL=C
local string="$*"
local length="${#string}"
local char
for (( i = 0; i < length; i++ )); do
char="${string:i:1}"
if [[ "$char" == [a-zA-Z0-9.~_-] ]]; then
printf "$char"
else
printf '%%%02X' "'$char"
fi
done
printf '\n' # opcional
}
urlencode "$@"
Exemplo de uso
Vejamos o código em ação:
$ ./urlencode isso é só a minha codificação
isso%20%C3%A9%20s%C3%B3%20a%20minha%20codifica%C3%A7%C3%A3o
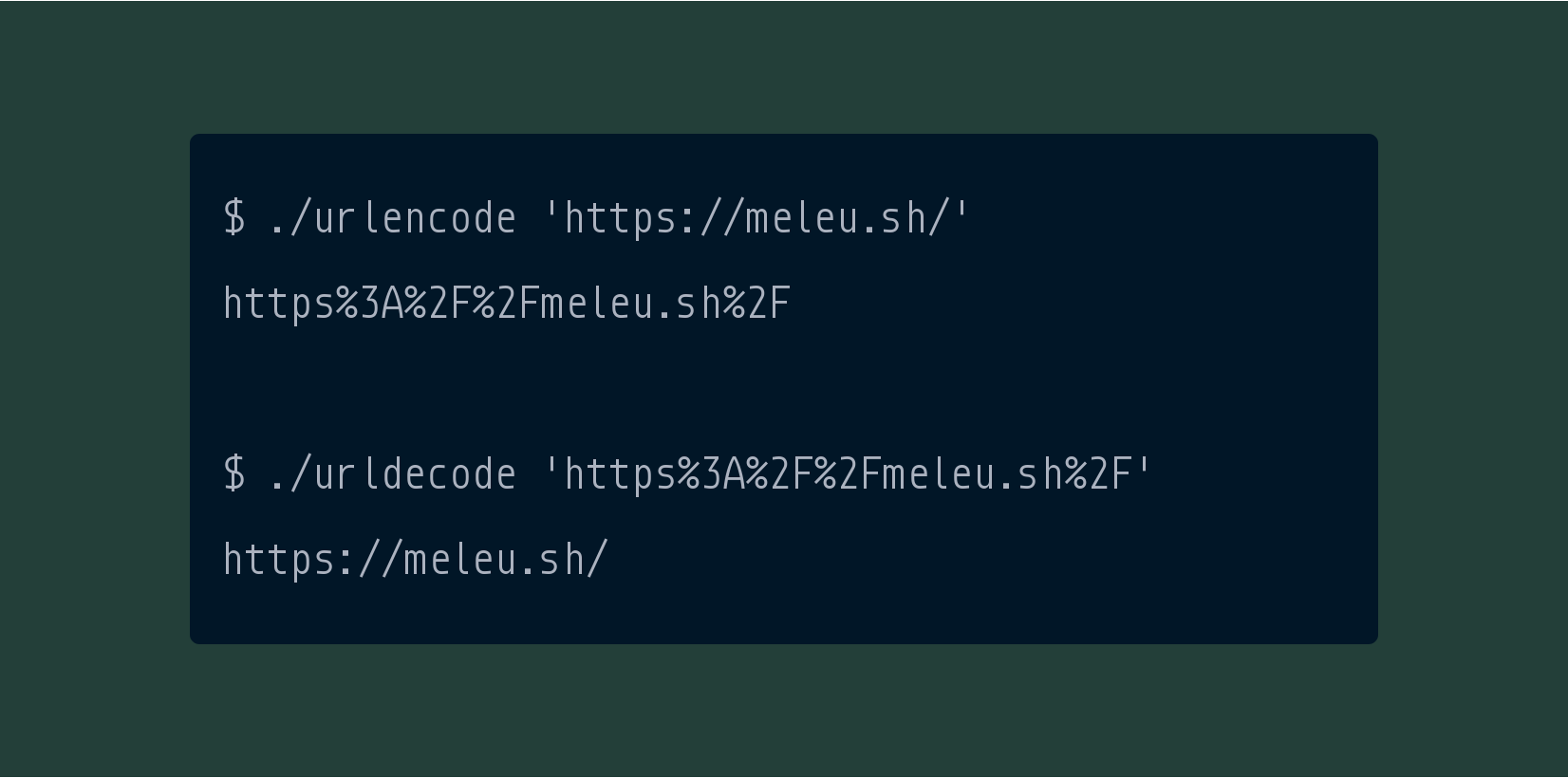
$ ./urlencode https://meleu.sh/
https%3A%2F%2Fmeleu.sh%2F
Explicando o código
Vamos a uma explicação detalhada do que está acontecendo em cada trecho da função:
local LC_ALL=C
A variável de ambiente LC_ALL serve para forçar um comportamento “portável” para todas as configurações de localização existentes. Usamos o modificador local para que a alteração do LC_ALL seja feita apenas no escopo da função, não alterando seu comportamento globalmente. Ou seja, ao final da função, o LC_ALL de quem chamou a função urlencode não terá sido alterado.
Agora deixa eu tentar explicar pra que serve o LC_ALL.
Se você for no seu terminal e digitar o comando locale, você verá uma lista de variáveis começando com LC_. Elas definem alguns comportamentos do sistema no que se refere as especificidades de cada localização.
Este recurso têm por objetivo tornar o sistema mais familiar e amigável à linguagem do usuário. E quando usamos LC_ALL=C é como se estivéssemos dizendo para o shell que queremos usar configurações de Unix “original”.
Por exemplo, aqui no Brasil nós temos letras acentuadas, nosso separador de decimal é , vírgula, nossa moeda é representada por R$, etc. Todas essas configurações são definidas nas variávels LC_*, e a variável LC_ALL serve para impor seu valor sobre todas as outras variáveis LC_* (ex.: se você tem LC_NUMERIC="pt_BR.UTF-8" e LC_ALL="C", seu sistema vai se comportar como se LC_NUMERIC="C").
Um dos motivos de definirmos LC_ALL=C aqui, é para que as nossas letras acentuadas não “casem” com o padrão [a-zA-Z]. O exemplo a seguir mostra isso bem claramente:
$ LC_ALL='pt_BR.UTF-8'
$ [[ é = [a-z] ]] && echo sim || echo nao
sim
$ # com 'pt_BR.UTF-8', o caracter 'é' está dentro do intervalo [a-z]
$ LC_ALL='C'
$ [[ é = [a-z] ]] && echo sim || echo nao
nao
$ # com 'C', o mesmo caractere nao esta no intervalo [a-z]
$ # (e eu tambem nao consigo escrever letras acentuadas normalmente)
Espero ter ficado claro. Agora vamos prosseguir com o código:
local string="$*"
local length="${#string}"
local char
Primeiro pegamos todos os argumentos e colocamos na variável string. Em seguida armazenamos em length o número de caracteres presentes em string.
A variável char será usada para analisarmos cada caracter de string no loop que vem a seguir
for (( i = 0; i < length; i++ )); do
char="${string:i:1}"
if [[ "$char" == [a-zA-Z0-9.~_-] ]]; then
printf "$char"
else
printf '%%%02X' "'$char"
fi
done
Um loop for estilo C foi utilizado para facilitar a manipulação do índice i.
O que acontece em char="${string:i:1}" é atribuir à char apenas o caractere presente na posição i da string. Aquela sintaxe significa algo assim: ${string:posicaoInicial:numeroDeCaracteres}. Portanto, a cada iteração do loop estamos testando apenas um caractere da string.
No if checamos se o caracter é válido para URLs. Lembra daquele LC_ALL=C que usamos lá no começo da função? Ele serve para nos ajudar aqui.
A lista de caracteres válidos para URL são dígitos de 0 a 9, letras maiúsculas e minúsculas de A a Z, traço -, ponto ., sublinhado _ e til ~. Escrevendo esse padrão para bash temos [a-zA-Z0-9.~_-]
Se o caracter for válido, simplesmente imprime. Mas se for inválido (o else), executaremos um printf um pouco obscuro, e que precisa de uma explicação mais detalhada:
printf '%%%02X' "'$char"
A sequência %%%02X significa:
%%: um%sinal de percentual literal%02X: formato hexadecimal, usando letras maiúsculas paraA-F, com dois dígitos e precedido de0zero se necessário.
O argumento "'$char" tem uma pequena sutileza: aquela ' aspa simples única no começo (observe que não tem o “fechamento” dela no final). Essa aspa simples significa que você quer passar o valor ASCII numérico do caractere que vem a seguir.
Veja esse exemplo pra ficar mais claro:
$ printf "%d\n" "a"
-bash: printf: a: número inválido
0
$ # lembrando: 'a' em decimal na tabela ASCII, é 97
$ printf "%d\n" "'a"
97
Pois é amigos… Esse macetinho obscuro está “escondido” lá manpage do bash, na parte que explica sobre o printf. Ali no penúltimo parágrafo, como quem não quer nada, tem uma frasezinha dizendo (tradução livre):
(…) se o primeiro caractere é uma aspa simples ou dupla, o valor será o valor ASCII do caractere a seguir.
Agora, lembra daquele LC_ALL=C lá do início da função? Também precisamos dele aqui para que esse printf gere a saída que precisamos. Veja só a diferença:
$ LC_ALL='pt_BR.UTF-8'
$ printf '%d\n' "'á"
225
$ LC_ALL=C
$ printf '%d\n' "'á"
195
E assim acabamos o loop.
Por fim temos um opcional
printf '\n' # opcional
Apenas para colocar uma nova linha no final da string.
urldecode()
Para decodificar é um pouco mais simples:
#!/usr/bin/env bash
#
# urldecode - decodificando de urlencoded para texto legível
urldecode() {
local encoded="${*//+/ }"
printf '%b\n' "${encoded//%/\\x}"
# o '\n' acima é opcional
}
urldecode "$@"
Exemplo de uso
$ ./urldecode 'https%3A%2F%2Fmeleu.sh%2F'
https://meleu.sh/
Explicando o código
A primeira linha coloca em encoded todos os argumentos passados para a função, substituindo + por espaço em branco.
Na linha do printf, especificamente no trecho ${encoded//%/\\x} pegamos o encoded e substituímos todos os sinais de % porcentagem por \x.
Demonstração:
$ encoded='%3A'
$ echo "${encoded//%/\\x}"
\x3A
Uma vez que substituímos todos os % por \x, o printf %b finaliza o serviço, pois o formato %b serve exatamente para lidar com essas sequencias de escape com contrabarra.
Demonstração:
$ printf '%b\n' '\x3A'
:
Portanto, o resultado do printf já será o conteúdo de encoded com os códigos hexadecimais já devidamente “traduzidos” para o caractere legível correspondente.
Ufa! Por hoje é “só”…